

Что такое Chatterbox-Turbo
Chatterbox-Turbo — это нейросеть для клонирования голоса и озвучки текста. По сути, это первый серьёзный удар открытого сообщества по конкурентам вроде ElevenLabs, которые долгое время доминировали на рынке синтеза речи.
Главная сила Chatterbox-Turbo — это управление эмоциями и скорость работы. У тебя есть прямой контроль над интенсивностью и выразительностью голоса, чего часто не хватает в других решениях. Плюс движок работает с низкой задержкой — под 200 миллисекунд, что позволяет использовать его даже для интерактивных приложений и диалогов в реальном времени. Это не шутка — для сравнения, ElevenLabs генерирует речь в среднем за 2.38 секунды.
Технически Chatterbox построен на базе Llama (0.5B параметров) и обучен на 500 тысячах часов очищенного аудиоконтента. Это означает, что модель натренирована на огромном объёме реальных голосов и выглядит достаточно стабильно. Модель поддерживает 23 языка прямо из коробки, включая русский, английский, французский, китайский и ещё кучу других. Сообщество может добавлять новые языки, так что эта цифра будет только расти.
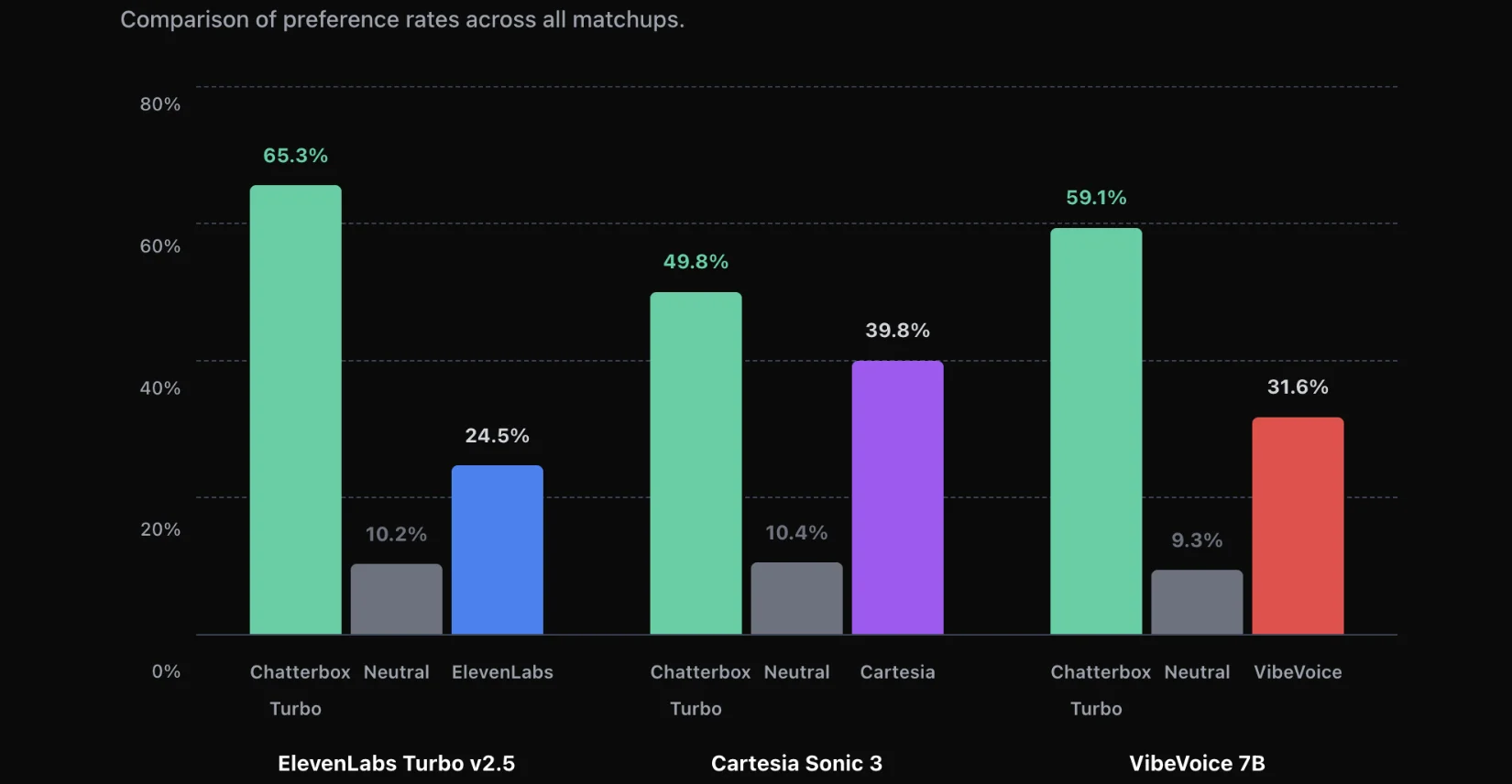
В слепых тестах, когда эксперты не знают, какой голос от какой системы, 63.75% выбирали Chatterbox как более качественный вариант. Это может показаться не так впечатляюще (раньше я видел эти цифры для других инструментов), но для открытого проекта это достаточно серьёзный результат.
Ещё одна любопытная деталь — все аудиофайлы, созданные Chatterbox, содержат скрытый водяной знак (PerTh). Это не слышно человеческому уху и выживает даже после MP3-сжатия, но позволяет доказать авторство и защитить от неправомерного использования. В эпоху deepfakes и синтетического контента это стало почти необходимостью.
Ключевые возможности Chatterbox-Turbo
Мультиязычный синтез речи с нулевым обучением
Ты можешь взять 10-15 секунд аудиоклипа на любом языке и Chatterbox-Turbo сразу же скопирует этот голос и начнёт генерировать речь на том же языке. Не нужно кучи обучающих примеров, не нужно долгой обработки — прямо в реальном времени.
Нейросеть поддерживает арабский, датский, немецкий, греческий, английский, испанский, финский, французский, иврит, хинди, итальянский, японский, корейский, малайский, нидерландский, норвежский, польский, португальский, русский, шведский, суахили, турецкий и китайский. Это охватывает большинство основных языков мира, хотя и не все. Например, не видно официальной поддержки корейского, тайского или вьетнамского (кроме китайского из китайской группы).
Процесс устроен следующим образом: ты записываешь 10-15 секунд речи на нужном языке, загружаешь это в Chatterbox, и нейросеть улавливает акцент, скорость речи, тон. Потом ты можешь написать любой текст на этом языке, и получишь аудио с голосом того же человека. Это работает потому, что модель использует т.н. ″zero-shot cloning″ — у неё достаточно опыта (благодаря огромным объёмам обучающих данных), чтобы справиться даже без специальной подготовки под конкретный голос.
Управление эмоциональной выразительностью
В Chatterbox есть специальный параметр ″exaggeration″ (преувеличение), который позволяет контролировать, насколько выразительным будет голос. Это работает как ползунок: низкие значения дают нейтральную, спокойную речь, высокие — это буквально драма и экспрессия, как у актёра театра на сцене.
Это критически важно для видеоконтента и создания персонажей. Представь, что ты озвучиваешь анимационный сериал. Для одного персонажа нужна спокойная, размеренная речь, для другого — живая, с интонациями. В других TTS-системах ты просто генерируешь две разные версии и выбираешь, что нравится. В Chatterbox ты просто крутишь ползунок и слышишь результат сразу.
Система рекомендует стандартные значения: exaggeration=0.5 и cfg_weight=0.5 работают хорошо для большинства текстов. Но если нужна максимальная экспрессия, можешь поднять exaggeration до 0.7-1.0. Осторожнее — это может ускорить речь, так что потом придётся понижать cfg_weight для компенсации скорости.
Ультра-низкая задержка
Chatterbox генерирует аудио менее чем за 200 миллисекунд. Это означает, что если ты запустишь его в облаке или на локальном сервере, пользователь услышит результат почти мгновенно. Для сравнения: ElevenLabs при синтезе короткого текста даёт задержку в 2-3 секунды, а длинные тексты могут ждать вообще несчастно долго.
Это не просто нерелевантно для какого-то редкого случая — это критично для интерактивных приложений. Если ты делаешь голосового ассистента, чатбота с озвучкой или игру с диалогами в реальном времени, задержка в 2 секунды будет ощущаться как вечность. Пользователь скажет что-то, а ответ придёт с заметной паузой. Chatterbox решает эту проблему.
На практике это работает так: если у пользователя мощный компьютер или приложение запущено на облачном сервере с хорошей конфигурацией, ответ приходит настолько быстро, что кажется живым голосом. Это открывает двери для приложений типа виртуальных ассистентов, которые раньше были затратно реализовывать.
Тут есть нюанс: скорость зависит от железа. На старых компьютерах или слабых CPU будет медленнее. Пользователи на Reddit сообщают, что на RTX 3090 модель генерирует речь на скорости реального времени или чуть быстрее (для 100 символов — 3-5 секунд). На CPU будет значительно медленнее, но всё равно быстрее, чем у конкурентов.
Встроенный водяной знак для защиты авторских прав
Каждый аудиофайл, созданный Chatterbox, автоматически получает скрытый водяной знак PerTh (Perceptual Threshold Watermarking). Это не видимо человеческому уху, не влияет на качество звука, но позволяет доказать, что это синтетический контент, созданный именно Chatterbox.
Зачем это нужно? На фоне растущих опасений по поводу дипфейков, такой знак становится защитой против неправомерного использования и подделок. Если кто-то скачает твоё аудио и попытается выдать его за свой контент, водяной знак покажет истину. Более того, этот знак выживает даже после MP3-сжатия и других типичных преобразований аудио.
В практическом смысле: ты генерируешь аудио, опубликуешь его на YouTube или подкаст-платформе, и можешь быть уверен, что твой контент отмечен. Это особенно важно, если ты продаёшь синтезированный контент или используешь его в коммерческих целях. Водяной знак — это твой сертификат подлинности.
Открытый исходный код и полная кастомизация
Весь код Chatterbox находится на GitHub под лицензией MIT. Это означает, что ты можешь взять исходный код, модифицировать его под свои нужды, встроить в свой проект, и никто тебя не будет преследовать в судах. Это совсем не то, что проприетарные решения ElevenLabs, которые ты можешь только использовать через API.
Кастомизировать можно вообще всё: архитектуру модели, обучающие данные, параметры вывода, всё что угодно. Хочешь добавить новый язык? Пожалуйста, сообщество будет благодарно. Хочешь оптимизировать модель под свой железо? Делай. Нужна интеграция со своей системой? Интегрируй как хочешь.
Для разработчиков это огромное преимущество. Вместо того чтобы быть привязанным к одной компании и её условиям, ты контролируешь весь процесс. Если Resemble AI вдруг повысит цены или закроет API, твой проект будет продолжать работать. Это долгосрочная безопасность и независимость.
Условия использования Chatterbox Turbo
Chatterbox-Turbo предлагается в двух вариантах: полностью бесплатный открытый исходный код (который ты скачиваешь с GitHub и запускаешь локально или на своём сервере) и облачный сервис Resemble AI с платными тарифами для удобства.
Вариант 1: Открытый исходный код (полностью бесплатно)
Если ты разработчик и готов потратить полчаса на установку, можешь просто скачать код из GitHub, установить зависимости и запустить локально. Это бесплатно навечно, ограничений на использование нет. Минусы: требует установки Python, понимания командной строки и достаточно мощного компьютера (нужна видеокарта с 6.5 ГБ VRAM для нормальной скорости). На слабом железе медленно, но будет работать.
Вариант 2: Облачный сервис Resemble AI (платно)
Если тебе нужно удобство облака и не хочешь возиться с установкой, есть официальный сервис от Resemble AI. Здесь всё готово в веб-интерфейсе, можешь генерировать голоса прямо из браузера, есть инструменты редактирования и т.д.
| Параметр | Creator (стартовый) | Professional (основной) | Business (масштаб) | Enterprise |
|---|---|---|---|---|
| Цена в месяц | $19 | $99 | $699 | По договорённости |
| Включено времени речи | 15,000 секунд | 45,000 секунд | 360,000 секунд | Неограниченно |
| Быстрые клоны | 3 | 20 | 500 | Неограниченно |
| Профессиональные клоны | 1 | 1 | 3 | Неограниченно |
| Параллельные запросы | 2 | 5 | 15 | По договорённости |
| Поддержка | Стандартная | Стандартная | Стандартная | Выделенная |
На что обратить внимание при выборе тарифа:
- Creator — подходит для экспериментов, небольших проектов или если ты генерируешь озвучку для одного видео в неделю. 15,000 секунд это примерно 4 часа аудио в месяц. Пересчитаем: если ты озвучиваешь часовое видео, хватит на одно видео в неделю.
- Professional. Хороший выбор выбор для создателей контента. 45,000 секунд (12.5 часов) в месяц — это достаточно для двух-трёх полноценных видеоуроков или 15-20 коротких видео.
- Business — для компаний, которые активно используют TTS в своих приложениях или масштабируют производство контента. 360,000 секунд уже близко к неограниченному использованию для большинства сценариев.
- Enterprise — индивидуальные условия для больших корпораций с собственной инфраструктурой.
Есть также вариант ″Pay as you go″ — для периодического использования. Ты просто покупаешь кредиты и используешь их по мере необходимости. Цена зависит от модели (Lite или Pro): около 0.03 доллара за минуту для Lite и 0.018 доллара за минуту для Pro. Кредиты не истекают, можешь их копить.
Бесплатный пробный период включает 150 секунд синтеза на облаке — этого хватит, чтобы попробовать интерфейс и понять, подходит ли сервис.
Кому подходит Chatterbox-Turbo
Кому стоит использовать Chatterbox-Turbo:
Если ты разработчик, который хочет встроить TTS в своё приложение и не хочет зависеть от облачных сервисов и их ценовой политики — это твоё решение. Скачай на GitHub, запусти локально, встрой в код, и готово. Никаких ежемесячных счётов, никакой зависимости от интернета (если всё запущено на локальной машине).
Если ты создатель видеоконтента на YouTube, TikTok, Twitch или Podcast-платформе и нужна качественная озвучка, но не хочешь платить ElevenLabs или нанимать дикторов — используй облачный сервис Resemble AI. За 19-99 долларов в месяц ты получаешь профессиональный результат с полным контролем над голосом и эмоциональностью.
Если ты работаешь над AI-агентом, чатботом или интерактивным приложением, где речь должна звучать в реальном времени — Chatterbox идеален. Его скорость позволяет создавать ощущение живого разговора, что другие TTS-системы просто не могут дать.
Если ты озвучиваешь игры, анимацию или видеопроизводство, где нужно много разных голосов и контроль над интонацией — Chatterbox позволяет клонировать столько голосов, сколько тебе нужно, и полностью контролировать выразительность каждого персонажа.
Кому не стоит использовать:
Если ты полный новичок в технологиях и не хочешь разбираться с GitHub, Python и командной строкой — тебе нужно использовать облачный сервис через веб-интерфейс, а не скачивать код. И это нормально, для этого существует платный вариант.
Если твой проект требует очень большого количества одновременных синтезов речи (более 15-20 одновременно) и ты хочешь использовать облако без предварительного обсуждения с компанией — то Enterprise план может быть единственным вариантом, и о стоимости стоит договаривать отдельно.
Если ты ищешь TTS с огромной библиотекой предустановленных голосов и не хочешь выбирать через клонирование — ElevenLabs может быть удобнее. У них тысячи готовых голосов, у Chatterbox — только те, которые ты сам создашь из образцов. Но качество Chatterbox выше, так что это компромисс между удобством выбора и качеством результата.
Заключение
Chatterbox-Turbo — это серьёзный игрок на рынке синтеза речи, который появился в нужное время. Открытый исходный код + производственное качество + низкая задержка + управление эмоциональностью — это комбинация, которую не найдёшь в других бесплатных моделях.
Если ты не готов платить подписку и хочешь полный контроль, скачивай с GitHub. Если нужен удобный облачный интерфейс, платные тарифы Resemble AI справедливо оценены и дешевле, чем предлагают конкуренты. Что бы ты ни выбрал, результат будет впечатляющим — голоса звучат натурально, задержка минимальна, и ты всегда можешь модифицировать всё под себя.