
Perplexity — это комбинация поисковой системы и языковой модели (LLM). Платформа анализирует информацию из поисковой выдачи и формирует развернутый ответ на запрос с помощью нейросетей.
Функционал сервиса можно интегрировать в свой проект с помощью API. В данной статье мы научимся использовать Perplexity API: рассмотрим доступные параметры и способы применения.
Начало использования Peplexity API
Пропустите данный раздел, если уже получили ключ API. Для отправки запросов мы будем использовать язык Python и библиотеку requests. В официальной документации Peplexity API доступны примеры на JS, PHP. Go, Java и утилиты командной строки Curl.
Как получить ключ API:
-
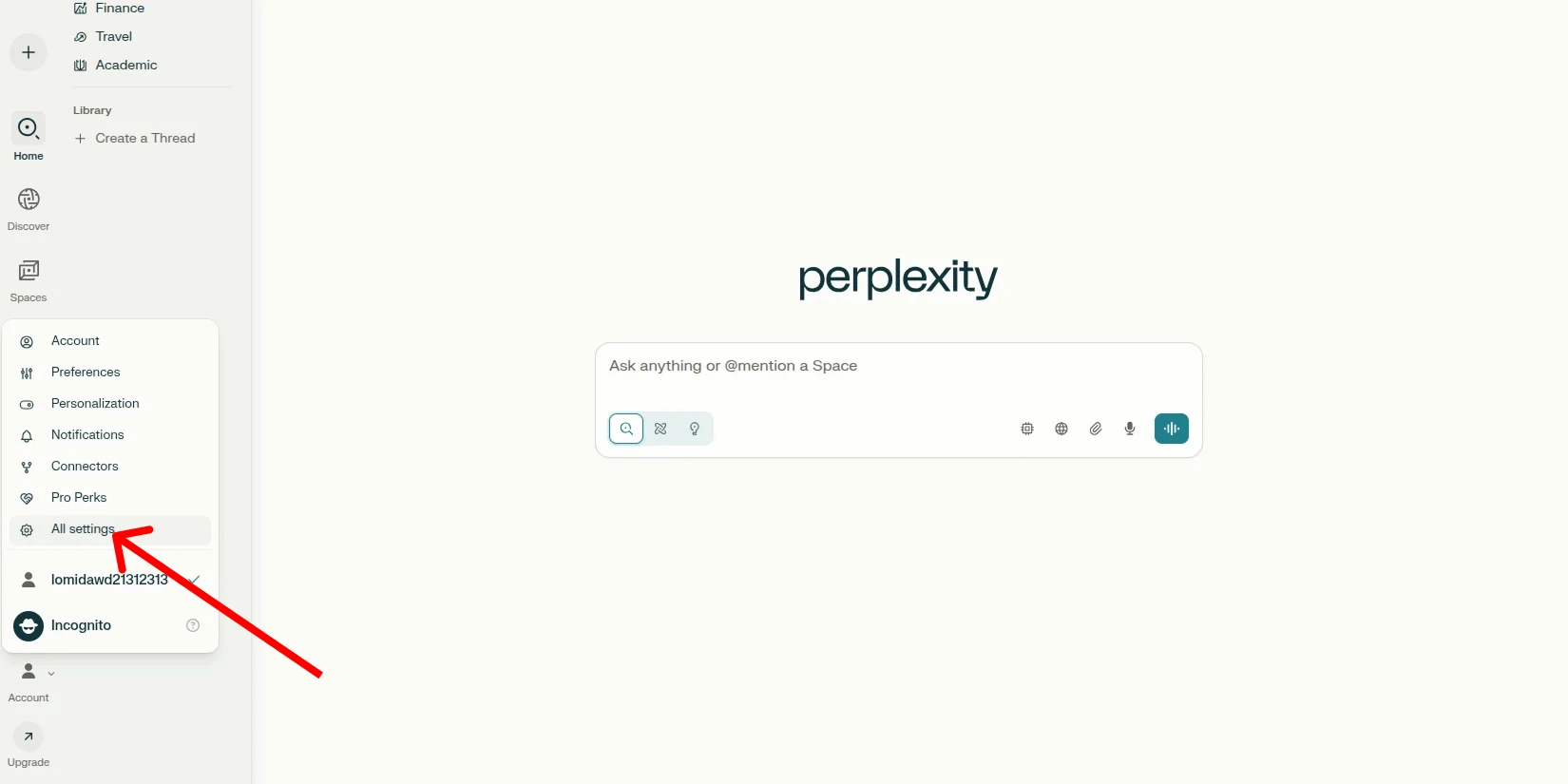
Переходим в раздел настройки API
На главной странице Perplexity в левом нижнем меню выбираем пункт «Account». Далее переходим раздел «All settings». На панели слева открываем пункт «API».
-
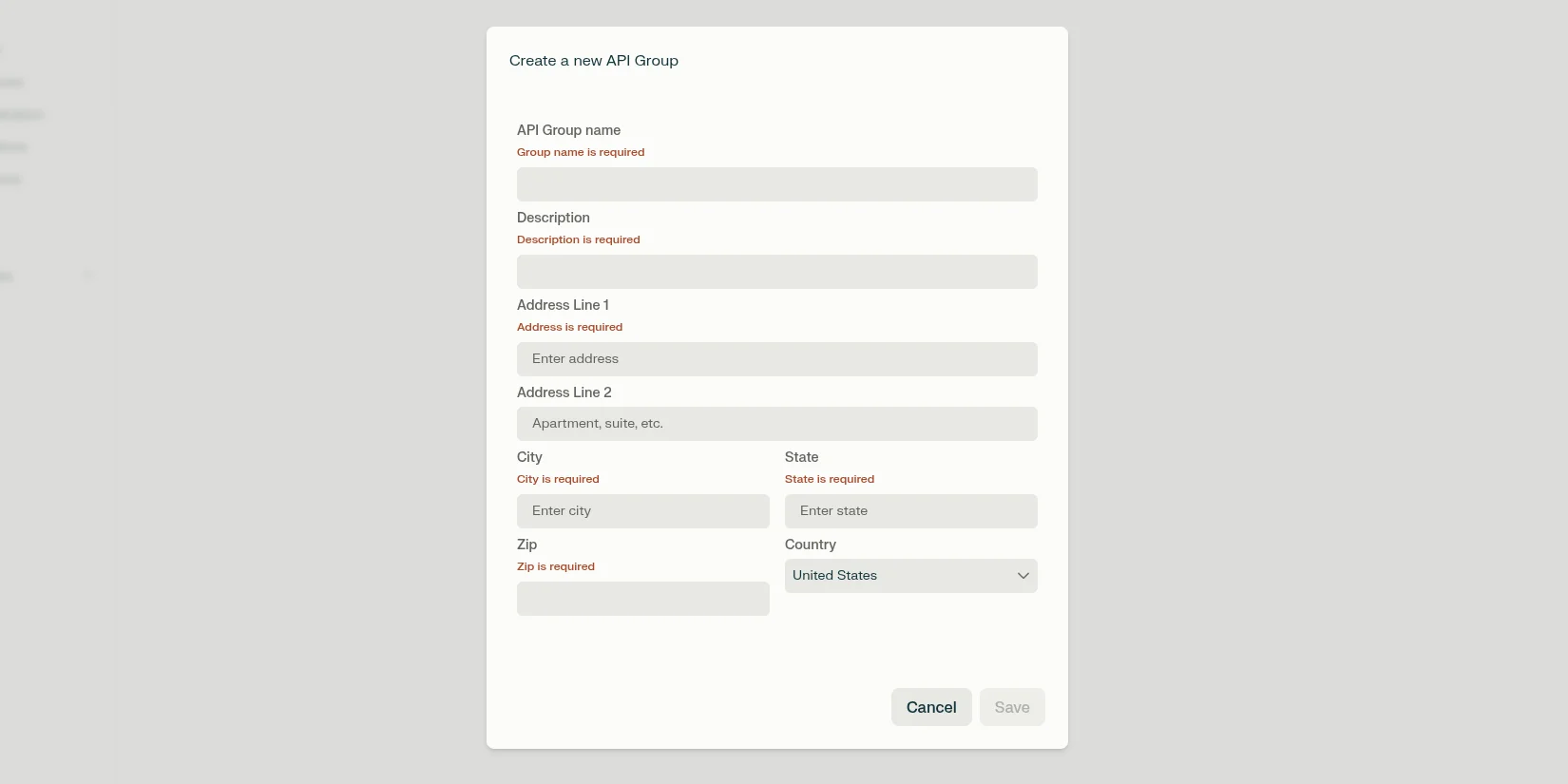
Создание новой группы API
Заполните необходимые поля. Для экономии времени пропустите необязательные. После завершения заполнения формы нажмите «Save».
-
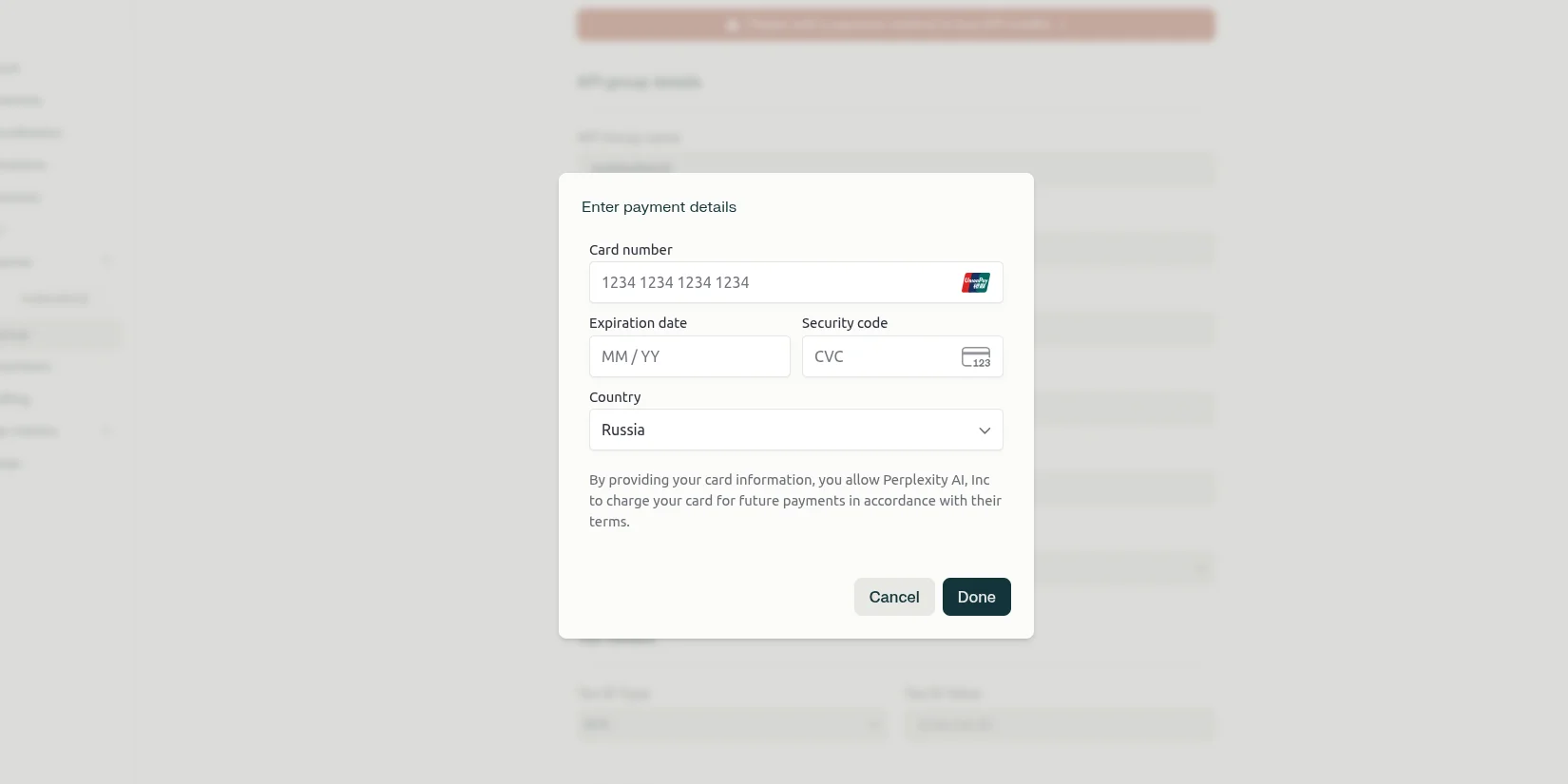
Указание платежных данных
Заполните данные банковской карты для пополнения баланса. На данном шаге не будет списания средств! Данные карты нужны для будущей оплаты. Если вы обладатель тарифа Pro, то вам предоставляется $5 на использование API каждый месяц.
-
Генерация ключей API
API-ключи создаются только при положительном балансе. Перейдите в раздел «API keys» и нажмите «Create key». API-ключи являются чувствительными данными и никогда не должны использоваться в клиентском коде или публичных репозиториях.
Первый запрос к API
Для реализации логики запросов к Perplexity API нам не потребуется установка дополнительных зависимостей. Достаточно языка Python и библиотеки requests.
Установить requests можно с помощью:
pip install requests
Далее напишем простой запрос с минимальным числом параметров:
import requests
API_KEY='************************************' # ключ API
authorization = f'Bearer {API_KEY}' # строка с заголовком авторизации
prompt = "Сколько планет в Солнечной системе?" # промпт
url = "https://api.perplexity.ai/chat/completions" # конечная точка API Perplexity
headers = {"Authorization": authorization} # словарь заголовков HTTP-запроса с данными авторизации
payload = {
"model": "sonar", # выбор модели
"messages": [
{"role": "system", "content": "Be precise and concise."}, # системный промпт
{"role": "user", "content": prompt} # пользовательский промпт
]
}
response = requests.post(url, headers=headers, json=payload).json() # отправка запроса на сервер Perplexity API
answer = response['choices'][0]['message']['content'] # ответ на наш вопрос
search_results = response['search_results'] # источники, на которые опиралась нейросеть
prompt_tokens = response['usage']['prompt_tokens'] # кол-во входных токенов
completion_tokens = response['usage']['completion_tokens'] # количество токенов в сгенерированном ответе
Мы отправляем POST-запрос к API Perplexity и преобразуем ответ в формат словаря Python. Давайте разберём запрос более подробно:
- url. Указывает конечную точку API Perplexity для получения ответов на вопросы (chat completions);
- headers. Создание словаря заголовков HTTP-запроса с данными авторизации. Bearer — ключевое слово, указывающее, что с помощью следующего далее ключа API вы получаете доступ к определенным ресурсов без дополнительной авторизации;
- model. Указание конкретной нейросети для формирования ответа;
- messages. Словарь, содержащий системный и пользовательский промпт;
- response. Объект с ответом модели. Содержит данные об использованных токенах, источниках и сам ответ.
Perplexity API имеет обратную совместимость с OpenAI API. Переезд проекта с одного провайдера на другой не должен составить труда.
Доступные модели
Все модели Perplexity собирают данные из интернета (кроме r1-1776) и формируют ответ с цитированием источников. Это принципиально отличает их от традиционных языковых моделей, которые опираются только на данные обучения.
Честный обзор на лучшую ИИ-платформу для поиска в интернете.
Поисковые модели
Sonar представляет собой базовую поисковую модель с контекстом 128,000 токенов. Идеально подходит для получения определений, фактов и ответов на простые вопросы. Баланс между стоимостью и скоростью.
Sonar Pro является флагманской моделью Perplexity с наиболее продвинутыми поисковыми возможностями. Модель поддерживает контекстное окно до 200,000 токенов и обеспечивает глубокие исследования с высокой точностью цитирования источников. Sonar Pro подходит для многоэтапных задач и предоставляет в 2 раза больше ссылок.
Модели рассуждений
Sonar Reasoning — базовая версия модели рассуждений для решения задач, требующих логического мышления. Подходит для быстрого решения задач средней сложности.
Sonar Reasoning Pro — продвинутая модель для сложных логических задач, использующая цепочки рассуждений. Модель обеспечивает глубокий анализ и пошаговые рассуждения. Подходит для работы со сложными темами, требующими многоэтапного анализа.
Исследовательские модели
Sonar Deep Research специализируется на проведении широких исследований с множеством источников. Идеально подходит для подробных отчётов, углубленного анализа, а также для проектов, требующих объединения источников информации. Модель может готовить ответ до 30 минут, поэтому не рекомендуем использовать для поверхностных вопросов.
Офлайн модели
R1-1776 — дообученная модель DeepSeek-R1, разработанная для предоставления объективной информации с минимальной цензурой. Нейросеть не использует источники в интернете для формирования ответа, а опирается на собственные знания.
Все модели поддерживают потоковую передачу ответов и предоставляют детальные метаданные об использованных источниках.
| Модель | Контекст | Веб-поиск | Цель |
|---|---|---|---|
| sonar-pro | 200k | Флагманская поисковая модель | |
| sonar | 128k | Быстрый поиск фактов | |
| sonar-deep-research | 128k | Глубокие исследования и детальные отчёты | |
| sonar-reasoning-pro | 128k | Продвинутая модель для сложных задач | |
| sonar-reasoning | 128k | Базовая модель для логических задач | |
| r1-1776 | 128k | Дообученная DeepSeek для офлайн-поиска |
Параметры запросов к Perplexity API
В данном разделе разберём самые популярные параметры запросов. Ранее мы уже встретили 2 обязательных параметра: model и messages. Полный список параметров с примерами вы можете найти в официальной документации Perplexity API.
Параметры управления генерацией
Данный список параметров отвечает за качество генерируемого ответа. По умолчанию установлены оптимальные параметры, поэтому экспериментировать необязательно.
max_tokens
Максимальное количество токенов в ответе, возвращаемых API. Контролирует длину ответа модели. Если ответ превысит это ограничение, он будет сокращен. Более высокие значения позволяют получать более длинные ответы, но могут увеличить время обработки и затраты.
Одним из способов контроля расходов заключается в поиске оптимального значения max_tokens, при котором мы получим исчерпывающий ответ, но не переплатим за количество токенов.
temperature
Значение параметра варьируется от 0 до 2. Более низкие значения (например, 0,1) делают результат более детерминированным и менее творческим. Более высокие значения (например, 1,5) делают результат более случайным и креативным.
Используйте более низкие значения для поиска фактов и более высокие — для творческих приложений. Значение по умолчанию — 0,2.
top_p и top_k
Параметр top_p управляет разнообразием генерируемого текста, рассматривая только те токены, совокупная вероятность которых превышает значение top_p. Более низкие значения (например, 0,5) делают выходные данные более детерминированными, в то время как более высокие значения (например, 0,95) позволяют получать более разнообразные выходные данные. Часто используется в качестве альтернативы температуре. Значение по умолчанию — 0,9.
top_k ограничивает модель рассматривать только k наиболее вероятных следующих токенов. Более низкие значения (например, 10) делают выходные данные более детерминированными, в то время как более высокие значения позволяют получать более разнообразные выходные данные. Значение 0 отключает этот фильтр. По умолчанию фильтр отключен.
stream
При включении параметра ответ будет передаваться по частям, создавая видимость непрерывной генерации. Значение по умолчанию — False.
Далее рассмотрим пример использования описанных параметров. Обратите внимание на построчный способ вывода ответа при использовании параметра stream,
import json
import requests
prompt = "Расскажи о заслугах Колмогорова"
url = "https://api.perplexity.ai/chat/completions"
headers = {"Authorization": authorization}
payload = {
"model": "sonar",
"messages": [
{"role": "system", "content": "Be precise and concise."},
{"role": "user", "content": prompt}
],
"max_tokens": 1200,
"temperature": 0.3,
"stream": True
}
with requests.post(url, json=payload, headers=headers, stream=True) as r:
for line in r.iter_lines(decode_unicode=True):
if line.startswith("data: "):
chunk = line[len("data: "):]
token = json.loads(chunk)
print(token["choices"][0]["delta"].get("content", ""), end="")
Параметры поиска и фильтрации
В данном списке находятся самые интересные параметры. С их помощью можно фильтровать источники по дате и типу.
search_mode
Задаёт режим поиска: академический (academic), по интернету (web) и по данным Комиссии по ценным бумагам США (sec). При академическом поиске нейросеть использует информацию из научных баз данных, журналов и публикаций. Функция полезна для студентов в сочетании с фильтром по дате публикации. По умолчанию используется поиск в интернете.
{
"search_mode": "academic"
}
search_domain_filter
Параметр позволяет контролировать, какие сайты будут использоваться для формирования ответа. С помощью символа "-" можно исключить домен из поиска. Используйте короткие названия доменов без протоколов и префиксов, например: используйте "ru.wikipedia.org" вместо "https://ru.wikipedia.org". В список можно добавить до 10 доменов.
"search_domain_filter": [
"<domain1>", # добавить домен
"-<domain2>", # исключить домен
...
]
web_search_options
Состоит из 2 необязательных параметров:
- search_context_size. Определяет объём контекста для поиска. Возможны следующие варианты: low (минимизирует контекст для экономии средств, но дает менее исчерпывающие ответы), medium (сбалансированный подход, подходящий для большинства запросов) и high (максимизирует контекст для получения исчерпывающих ответов, но требует более высоких затрат);
- user_location. Персонализирует результаты поиска на основе местоположения. Допустим, можно попросить найти лучшие рестораны рядом с вами.
{
"web_search_options": {
"search_context_size": "high",
"user_location": {
"latitude": 37.7749,
"longitude": -122.4194,
"country": "US"
}
}
}
search_recency_filter
Фильтрация по времени публикации:
- "hour" — последний час;
"day"- последний день;"week"- последняя неделя;"month"- последний месяц.
{
"search_recency_filter": "week"
}
search_after_date_filter и search_before_date_filter
Поиск от и до определенной даты. Параметры можно использовать вместе и отдельно.
{
"search_after_date_filter": "1/1/2025",
"search_before_date_filter": "12/31/2025"
}
last_updated_after_filter и last_updated_before_filter
Параметры позволяют выполнять фильтрацию по дате последнего изменения или обновления контента, а не по дате его первоначальной публикации.
{
"last_updated_after_filter": "3/1/2025",
"last_updated_before_filter": "3/5/2025"
}
reasoning_effort
Доступен только для модели sonar-deep-research. Контролирует, сколько вычислительных ресурсов ИИ использует на каждый запрос:
- "low" — быстрые и простые ответы при меньшем использовании токенов;
- "medium" — сбалансированный подход;
- "high" — более глубокие ответы при большем использовании токенов.
{
"reasoning_effort": "medium"
}
Продвинутое использование Perplexity API
В данном разделе мы научимся отправлять асинхронные запросы и получать ответы в структурированном виде с помощью JSON-схем и регулярных выражений.
Structured Outputs
Structured Outputs в Perplexity API — это возможность получать ответы от языковых моделей в строго определенном формате. Эта функция обеспечивает предсказуемую структуру данных в результате, что критически важно для интеграции с приложениями и обработки ответов.
Perplexity поддерживает два типа структурированных выходов:
- JSON Schema — для получения ответов в формате JSON согласно заданной схеме;
- Regex — для получения ответов, соответствующих регулярному выражению.
Получение ответа в формате JSON
Нам нужно сформировать JSON-схему с помощью библиотеки Pydantic. Поддерживаются, как простые, так и сложные схемы, например:
# pip install pydantic
from pydantic import BaseModel
from typing import List
class Address(BaseModel):
street: str
city: str
country: str
class Person(BaseModel):
name: str
age: int
addresses: List[Address]
Рекомендуется в промпте указывать требования о формате JSON и краткое описание полей схемы. Кроме того, в описании схемы с помощью Pydantic давайте полям говорящие имена, как в примере выше.
from pydantic import BaseModel
import requests
API_KEY='*********************************8'
authorization = f'Bearer {API_KEY}'
class AnswerFormat(BaseModel):
last_name: str
first_name: str
prompt = "Напиши обладателей Золотого мяча 2000 года. В ответе верни фамилию и имя футболиста в формате JSOM"
url = "https://api.perplexity.ai/chat/completions"
headers = {"Authorization": authorization}
payload = {
"model": "sonar",
"messages": [
{"role": "system", "content": "Be precise and concise."},
{"role": "user", "content": prompt}
],
"response_format": {
"type": "json_schema",
"json_schema": {"schema": AnswerFormat.model_json_schema()},
},
}
response = requests.post(url, headers=headers, json=payload).json()
print(response['choices'][0]['message']['content'])
# {"last_name": "Фигу", "first_name": "Луиш"}
Мы получили словарь, который легко распарсить с помощью Python. Таким образом, JSON-схема позволяет отправлять ответы для дальнейшей обработки, не переживая за несоответствие ожидаемому формату.
Использование RegEx
Регулярные выражения (RegEx) используются для задач, требующих точного извлечения конкретных форматов данных, таких как номера телефонов, email-адреса, IP-адреса и другие структурированные элементы.
import requests
API_KEY='******************************************8'
url = "https://api.perplexity.ai/chat/completions"
authorization = f'Bearer {API_KEY}'
headers = {"Authorization": authorization}
payload = {
"model": "sonar",
"messages": [
{"role": "system", "content": "Be precise and concise."},
{"role": "user", "content": "What is the customer service phone number for Apple?"},
],
"response_format": {
"type": "regex",
"regex": {
"regex": r"\d{3}-\d{3}-\d{4}"
},
},
}
response = requests.post(url, headers=headers, json=payload).json()
print(response["choices"][0]["message"]["content"]
# 189-275-2273
Для многих разработкиков воспоминания об изучении регулярных выражений вызывают боль и панические атаки. Из-за сложности использования некоторых выражений рекомендуем тестировать их перед использованием.
Хорошей практикой считается кэширования регулярных выражений с целью повышения производительности системы. Официальная документация по RegEx для Python находится здесь.
Отправка асинхронных запросов
Асинхронность позволяет отправить несколько запросов к API, не дожидаясь их выполнения. Количество одновременно обрабатываемых запросов зависит от уровня аккаунта.
import requests
url = "https://api.perplexity.ai/async/chat/completions" # меняем url
API_KEY='********************************'
authorization = f'Bearer {API_KEY}'
headers = {"Authorization": authorization, "Content-Type": "application/json"}
def send_request(prompt: str): # функция для отправки запроса
payload = {
"request": {
"model": "sonar-deep-research",
"messages": [
{
"role": "system",
"content": "Be precise and concise."
},
{
"role": "user",
"content": prompt
}
],
"max_tokens": 123
}
}
response = requests.post(url, json=payload, headers=headers)
return response.json() # получаем словарь с id запроса и его статусом
result = send_request(prompt="Напиши инструкцию по регистрации в Perplexity")
print(result)
Обратите внимание, что мы поменяли URL-адрес на другой, поддерживающий отправку нескольких запросов. Также пришлось внести небольшие изменения в тело запроса. В результате мы получим словарь с идентификатором и статусом запроса:
{'id': 'aa117ce5-77bf-466b-ad6a-3587f9a34e96',
'model': 'sonar-deep-research',
'created_at': 1752235543,
'started_at': None,
'completed_at': None,
'response': None,
'failed_at': None,
'error_message': None,
'status': 'CREATED'}
Статус "CREATED" означает, что запрос обрабатывается. С помощью id мы можем узнать статус задачи:
def poll_request_status(request_id):
url = f"https://api.perplexity.ai/async/chat/completions/{request_id}"
headers = {"Authorization": authorization, "Content-Type": "application/json"}
while True:
response = requests.get(url, headers=headers)
data = response.json()
if data.get('status') == 'COMPLETED':
return data.get('response')
time.sleep(10)
result = poll_request_status(request_id=result['id'])
print(result)
В данном коде каждые 10 секунд мы отправляем запрос к Perplexity API, чтобы получить статус задачи. Если задача выполнена, то возвращаем словарь с ответом, использованными источниками и другими параметрами.
Таким образом, вы можете отправлять несколько задач друг за другом, не ожидая выполнения предыдущих. Сохраняйте идентификаторы задач и периодически проверяйте их статус.
Условия использования Perplexity API
Давайте рассмотрим стоимость использования каждой модели и ограничения на количество запросов. Полную информацию об условиях использования можно найти здесь.
Цены на модели
Стоимость токенов зависит от выбранной модели. В таблице указана цена за 1 млн токенов.
| Модель | Входные токены (за 1млн) | Выходные токены (за 1 млн) |
|---|---|---|
| sonar-pro | $3 | $15 |
| sonar | $1 | $1 |
| sonar-deep-research | $2 | $8 |
| sonar-reasoning-pro | $2 | $8 |
| sonar-reasoning | $1 | $5 |
| r1-1776 | $2 | $8 |
Для модели sonar-deep-research присутствуют ещё 2 параметра:
- Reasoning Tokens. Токены, использованные в процессе рассуждения модели. $3 за 1 млн токенов;
- Citation Tokens. Токены, использованные для цитирования источников. $2 за 1 млн токенов.
Отслежить расход токенов можно в настройках в разделе «API billing». Доступна статистика отдельно по каждому виду токенов: входные, выходные, цитирование и рассуждения.
Лимиты
Rate Limits (ограничения скорости) в Perplexity API — это механизм контроля количества запросов, которые пользователь может отправить к API в течение определенного времени. Эти ограничения измеряются в RPM (requests per minute — запросов в минуту) и служат для обеспечения стабильности сервиса и справедливого распределения ресурсов между пользователями.
Perplexity использует систему тарифов (Usage Tiers), основанную на общей сумме пополнений баланса на аккаунте. Чем больше средств потратил пользователь, тем выше его тарифный уровень и больше доступных запросов.
| Уровень | Сумма пополнений баланса |
|---|---|
| Tier 0 | — |
| Tier 1 | $50 |
| Tier 2 | $250 |
| Tier 3 | $500 |
| Tier 4 | $1000 |
| Tier 5 | $5000 |
Такой подход помогает грамотно распределять ресурсы. Например, к Tier 0 относятся люди, которые только начали экспериментировать с Perplexity API. К Tier 5 чаще всего относятся компании с большим количеством пользователей. Естественно, компании нужно выделить больше ресурсов, чем начинающему пользователю. Полная информация об условиях для всех уровней можно найти здесь.
Часто задаваемые вопросы
Что такое Perplexity API?
Perplexity API — программный интерфейс, с помощью котоого вы можете интегрировать функции веб-поиска с цитированием источников в свой проект.
Можно ли использовать Perplexity API бесплатно?
Пользователи подписки Pro могут использовать Perplexity API бесплатно с расходом до $5 в месяц. Каждый месяц баланс восстанавливается обратно до $5.
Где найти документацию для Perplexity API?
Полная документация доступна на сайте Perplexity. В документации присутствует удобный поиск с помощью ИИ.
Присутствует ли веб-поиск в Perplexity API?
Да. Все модели, кроме r1-1776, поддерживают поиск информации в интернете и научных базах.
Какие модели доступны в Perplexity API?
Предоставлен доступ к собственным моделям Perplexity: r1-1776, Sonar, Sonar Pro, Sonar Reasoning, Sonar Reasoning Pro и Sonar Deep Research.
Где взять ключ для Perplexity API?
Ключ API можно получить в личном кабинете Perplexity. Для этого требуется создать новую группу и предоставить платежные данные (только при нулевом балансе). Более подробная информация доступна в нашей статье.